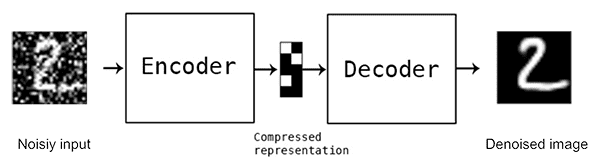
Model: "functional_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 14, 14, 32) 9248
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 7, 7, 32) 9248
_________________________________________________________________
up_sampling2d (UpSampling2D) (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 14, 14, 32) 9248
_________________________________________________________________
up_sampling2d_1 (UpSampling2 (None, 28, 28, 32) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 28, 28, 1) 289
=================================================================
Total params: 28,353
Trainable params: 28,353
Non-trainable params: 0
_________________________________________________________________