Entendimento das redes neurais recorrentes¶
- Redes neurais, em geral, não guardam informações na memória
Rede aplicada ao IMDB: treino utilizando cada review como um todo => feedfoward network
Processo de leitura do ser humano: processamento incremental, com informações mantidas na memória e entendidas conforme se lê
Rede neural recorrente: versão simplificada da leitura humana => processamento das sequências de texto sem perder a memória/contexto das sequências anteriores.
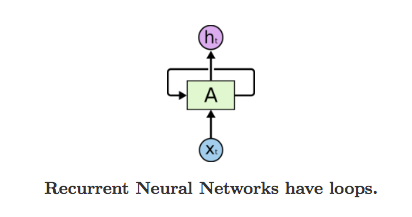
- Ainda assim, uma RNN considera um review por vez e de forma independente



